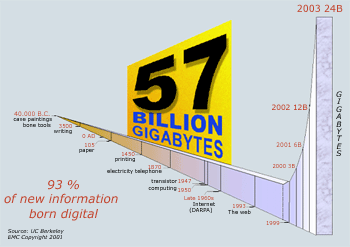
The pervasive use of computers, as well as tremendous advances in our ability to acquire, store and process data, has resulted in a spectacular increase in the amount of data we collect: Already in 2000 a UC Berkeley study estimated that the amount of digital data created in two years was larger than the amount created in all previous history, and in 2003 it was estimated that about 5 Exabytes (5∙10^18 bytes) of original information were produced in 2002. According to an estimate published in a February 2010 issue of The Economist, this number will grow to about 1200 Exabytes in 2010.
It seems inevitable that society will become increasingly data driven in the coming years, as e.g. advanced networked censors are incorporated in building, cars, phones, goods and even humans, and as new networked computing devises (phones, handhelds, GPS devices, etc.) become increasingly pervasive. The articles in the February 2006 issue of Nature, “2020 – Future of computing” highlights these trends in the sciences by describing the exponential growth (yearly doubling) of scientific data, and arguing that computer science will become paramount in all sciences. This trend was also the focus of another Nature special issue "Big Data - Science in the petabyte era" in 2008.
EFFICIENT ALGORITHMS
Handling of massive data requires algorithm
with good scale-up behavior, that is, algorithms that scales to be able to solve very large problems.
Even though advances in computer hardware have brought us continually faster machines, efficient algorithms are getting increasingly important because the size of datasets being processed are increasing at an even faster rate, and because we are increasingly using smaller computing devises.
Unfortunately, traditional algorithms theory is not adequate in many modern applications; one main reason being that computation is viewed as a simple process of transforming given input data into a desired output using a well-defined and simple machine model consisting of a processor and and (infinite sized) memory. This scenario is not realistic in modern applications where computation is increasingly being performed on massive amounts of data (larger than the main memory size) and on very diverse computation devices. This leads to software inadequacies when it comes to processing massive data. The MADALGO center will work to remedy this situation.
MADALGO - Center for Massive Data Algorithmics, a Center of the Danish National Research Foundation / Department of Computer Science / Aarhus University